Explore insights by category
Data and analytics | Finances and payments | Mental health | Patient and member engagement | Pharmacy care | Pharmacy management | Technology and automation | Value-based care | View all
Latest featured insights

E-book
Create meaningful change for the women in your workforce. Learn steps to help close the gap in health equity, improve health and lower costs.
![A Quarter-Century of Pharmacy Benefit Changes [E-Book]](/content/dam/optum-dam/images/business/pharmacy/hand-with-vial-1080x720.jpg)
E-book
Explore the dramatic changes in the years since 2000 — in drug performance and design, and especially affordability.

Article
Explore how evidence-based tools like The ASAM Criteria® Navigator and InterQual® Substance Use Disorders Criteria are helping payers and providers efficiently and effectively navigate the complex substance use disorder landscape today.
![Automation Strategies for Empowering Staff and Patients [Webinar]](/content/dam/o4-dam/images/professionals/company-meeting-1080x720.jpg)
On-demand webinar
Learn how to help transform hospital revenue cycle operations with healthcare automation.
Data and analytics

Article
Understand how routine clinical practice impacts information captured in real-world data (RWD).

On-demand webinar
Hear from experts in this Endpoints News webinar on the increasing importance of clinicogenomic data, including diverse phenotypic and genotypic profiles.

Video
Optum Life Sciences leaders break down common missteps when using RWD and how to create practical strategies to overcome them. Watch the video from STAT Summit.

Article
Providers collect data about patients every day. But what should they be considering — and doing — to put their clinical data to good use?
Finances and payments

Article
Discover 4 ways health plans can save money today — and in the future — by engaging with a digital claim payment partner.

Article
Learn how AI is changing the fraud case review process.
Article
The connection between money and health runs deeper than just costs — your employees rely on your benefits strategy for overall wellness.
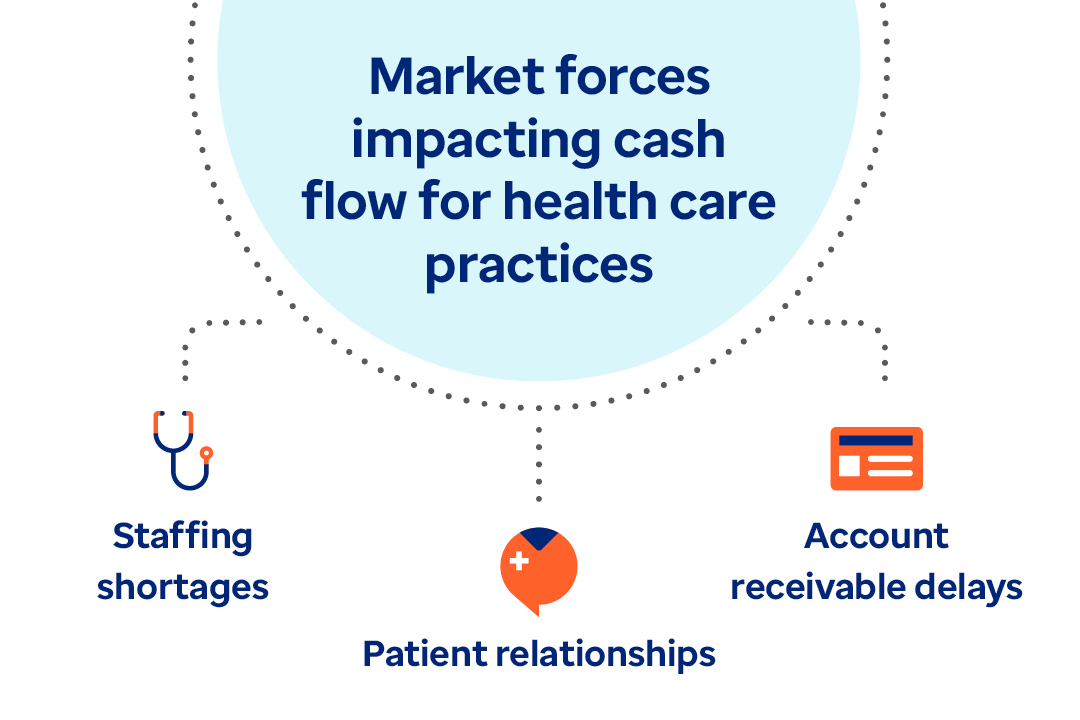
Article
Learn how payment delivery optimization can improve the healthcare financial cycle and bridge the gap between payers and providers.
Mental health


Video
When the Minnesota Fire Service needed emotional well-being support for their firefighters, Optum stepped in to help.

Article
Learn more about the current research on mobile crisis teams (MCTs), how to build an MCT as well as envision a future for them.

White paper
Create solutions to eliminate barriers to care and support members.
Patient and member engagement

Article
Learn how Optum Serve is helping to advance the health and well-being of Veterans and spouses in the trucking and cybersecurity workforce.

Guide
Learn how Optum Serve helped Veterans achieve health and wellness goals, promoted well-being, prevented illness and reduced the burden of chronic conditions.

White paper
Learn how Optum Serve supports Veterans through a whole-health approach to work and life.

Case study
Learn how Southwest Medical Associates (SMA) used the Optum platform to automate vaccine scheduling and reminders for both shots at once.
Pharmacy care

Video
Our infusion care ecosystem is based on a commitment to clinical innovation and providing consistent, convenient and compassionate care.

Article
Optum tackles the many issues infusion pharmacy care faces as it serves vulnerable patients with acute needs and complex conditions.

White paper
Learn about the impact on catheter lock therapy for home infusion patients with a central venous access device (CVAD).

Article
Specialty pharmacies deliver high-touch services to help patients stay adherent to treatment plans and live healthier lives.
Pharmacy management

Guide
Learn how identifying and addressing disparities in healthcare allows everyone to live their healthiest life.

On-demand webinar
From specialty pharmacy to drug affordability, our experts tackle your biggest pharmacy challenges.

Article
PBMs don’t cause high drug costs — they’re part of the solution. Our drug prices beat the “low cost” vendors.

Article
Discover what plan sponsors need to know to help remove or limit cost as a barrier to medication access.
Technology and automations

Case study
Using digital integration to ease administrative burdens can help you spend more time with patients and deliver positive patient outcomes.

White paper
Read the white paper for strategies on controlling fixed costs, efficiency and organizational flexibility.

Case study
See how Lima Memorial improved efficiency with advanced technology.

On-demand webinar
Watch the webinar to learn actionable strategies on tackling decreased hospital margins, increased labor costs and staffing shortages.
Value-based care

Article
A growing number of women are navigating cancer care. Targeted supports can make a difference in patient experience, outcomes and costs.

Article
Navigating a complex healthcare environment is challenging. Using hub and advocacy solutions together helps employers and employees alike.
![Revolutionizing Specialty Medication Management [E-book]](/content/dam/internal-resources/images/specialty-fusion-ebook-thumbnail-1080x720.jpg)
E-book
Get an in-depth assessment of the ways Specialty Fusion™ is revolutionizing specialty drug management.

E-book
Discover specialty medication management strategies to help you slow carve-out and stop member attrition.
All healthcare industry insights (579)
Filter
-

Patient education: The secret to success in risk adjustment and VBC
Effective patient education fosters adherence to medical treatments and promotes healthy patient behaviors, in turn facilitating successful risk adjustment and value-based care.
-

AI advancements bridge the gap to dual eligibility enrollment
See how AI-powered technology and personalized member engagement are helping to identify and enroll more members into Medicaid programs.
-

Maximizing CareSelect Imaging for value-based care
Discover how to transform your approach to clinical decision-making and advance your organization’s value-based care goals.
-

How organizations can support neurodiversity in the workplace
Recognizing the unique perspectives of neurodivergent individuals and creating an inclusive workplace can enrich and empower your teams.
-

Extracting value-based care insights from claims data
Actionable insights for health plans and providers to adopt a data-driven approach and achieve value-based care goals.
-

The Big Picture on Pharmacy
Meet Dr. Wig, Chief Clinical Officer for Optum Rx, and hear how we’re addressing cost and clinical trends in pharmacy.
-

Best practices for efficient medical record retrieval
Medical record retrieval is an essential task for healthcare providers and insurers, but it can often be a complex and time-consuming process.
-

Helping a member find support
See how one mother found in-the-moment support during a family crisis.
-

Optimize employee benefits with healthcare analytics
With the right tools, employers can transform employee benefits data into actionable insights that drive better experiences and add value.
-

Tailoring Medicare plans for specific populations
Learn some of the best practices and strategies for serving your members effectively through special needs planning and beyond.
-

Reduce length of stay and enhance resource efficiency
Learn more about how Optum Enterprise Intelligence Suite (EIS) enables best practices for achieving operational excellence.
-

How payers can prepare for the next wave of cellular therapy patients
CAR T-cell therapies have been remarkably successful and may become more widely available. Here’s how to get ready for a rise in these expensive treatments.
-

Regulations to watch: Spring 2025
Learn what’s at stake for pharmacy benefits sponsors as federal oversight changes and state legislative sessions begin.
-

Digital MSK tools: 5 important features
Digital MSK can improve outcomes while reducing costs. Learn how payers and employers can choose a program that delivers on health benefits and savings.
-

Small price hikes make for big drug prices
We know about the high prices for new drugs, but drug companies make most of their money from repeated small price increases on older drugs.
-

Help enhance coding accuracy with the HCC Tearsheet 2025
Accurate HCC codes are essential for effective care management and compliance.
-

Making inroads with maternal health
Learn how Indiana and Washington, D.C., are tackling critical maternal health equity disparities.
-

Quick and safe digital specialty pharmacy service
Optum Specialty Pharmacy leverages specialized expertise and resources with flexibility, delivering personalized care that drives better outcomes.
-

How real-world evidence can inform pharma strategies in 2025
Health economics and outcomes research (HEOR) can play a key role in helping the life sciences industry improve patient outcomes.
-

Transform your pharmacy benefits with end-to-end transparency
Pharmacy benefits should be clear and simple. Are they? In this latest e-book, see how true transparency drives better outcomes.
-

Social determinants of health in urban America
Learn more about addressing social determinants of health in Brooklyn, NY.
-

How small and emerging biopharma can generate real-world evidence
Here are questions small and emerging biopharma need to ask to generate meaningful evidence and be competitive.
-

Which growth strategy path is right for you?
Discover which growth strategy path is right for your health system.
-

Are your pharmacy benefits working hard enough?
Pharmacy benefits should be transparent, affordable and easy to use. Get clear on your pharmacy benefit manager’s value with these 3 questions.